Federated Agent Reinforcement Learning
Abstract
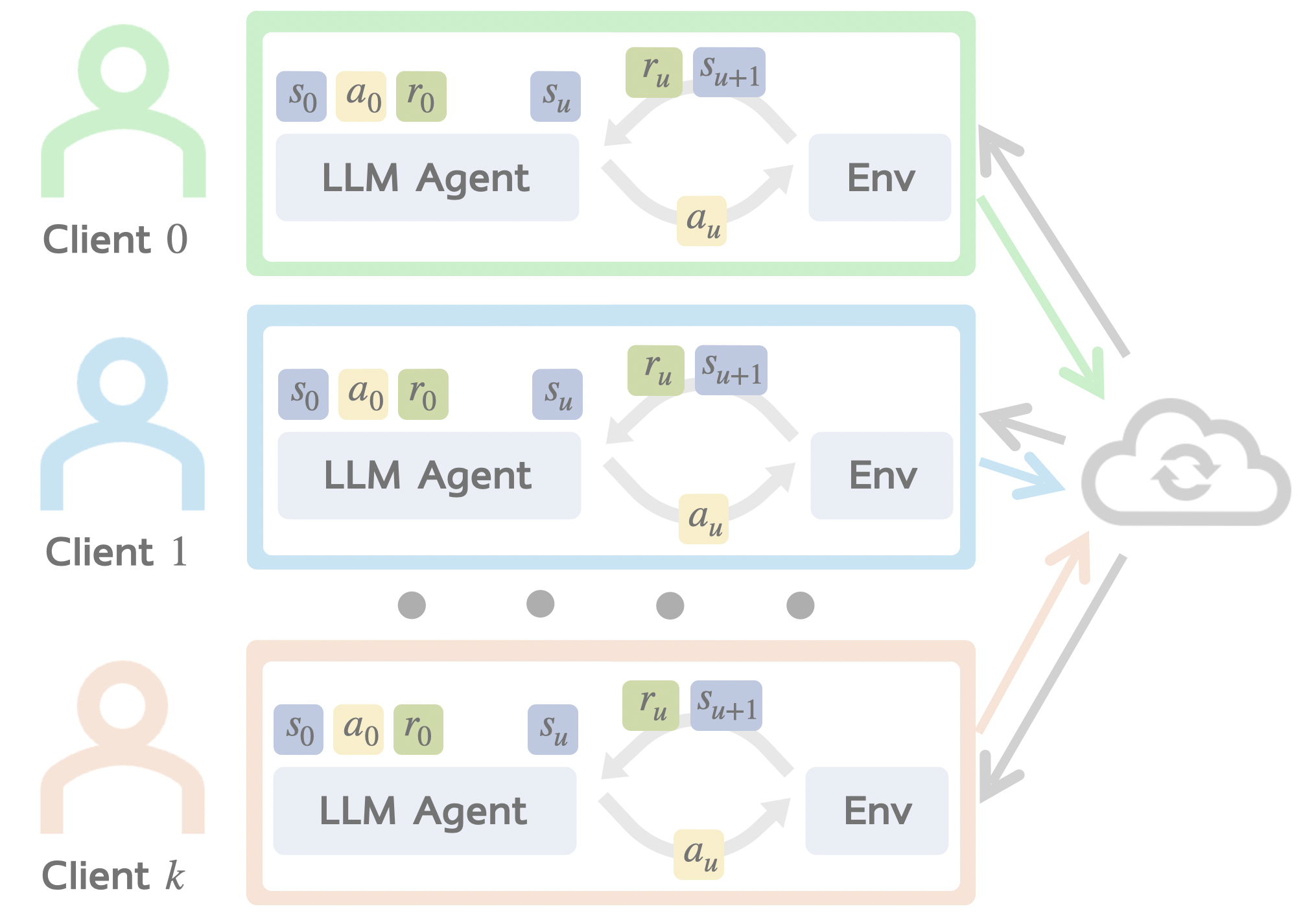
LLM-powered AI agents are trained on real-world user interactions, such as customer purchase queries in e-commerce (WebShop) or household routines in embodied environments (ALFWorld), data that is inherently private and cannot be centrally pooled. Can we train AI agents while protecting users' data privacy? We introduce FedAgent (Federated Agent Reinforcement Learning), a decentralized training paradigm where each client runs local RL, sends only model parameters to a server for aggregation, and keeps all data local. Unlike conventional federated RL with low-dimensional state/action spaces, FedAgent tackles the unique challenges of natural language state and action spaces, diverse tasks, and complex environment interactions. We construct FedAgentGym, the first decentralized agent learning environment with four LLM agents, two application scenarios, three decentralized settings, and a new two-level agent heterogeneity framework: Task Heterogeneity (Preference, Coverage, Hardness, i.e. what types, how many, and how hard are each client's tasks) and Environment Heterogeneity (clients interact with fundamentally different worlds). Empirically, FedAgent matches centralized training and is robust to all three axes of task heterogeneity, but environment mismatch alone collapses the shared policy to near-zero. We provide a theoretical explanation via a convergence bound that decomposes error into stochastic noise, task-level drift, and environment-level drift, and a σ²-Dominance Theory showing that the enormous gradient noise from exponential action spaces absorbs task divergence but cannot absorb the systematic conflict of environment divergence.
Algorithm
Client Partitioning Strategies
We define three novel client partitioning methods to systematically study heterogeneity challenges in decentralized agent learning.
Main Results
Performance comparison of Local Training, Centralized Training, and FedAgent across different LLM agents on ALFWorld and WebShop benchmarks.
Qwen2.5-1.5B-Instruct
| Method | ALFWorld (Success Rate %) | WebShop | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pick | Look | Clean | Heat | Cool | Pick2 | All | Score | Succ. | |
| Local (Client 21) | 42.9 | 25.0 | 38.5 | 37.5 | 14.3 | 14.3 | 29.7 | 69.9 | 57.0 |
| Local (Client 42) | 50.0 | 37.5 | 76.9 | 25.0 | 42.9 | 14.3 | 45.3 | 75.1 | 53.1 |
| Local (Client 84) | 50.0 | 37.5 | 46.2 | 25.0 | 28.6 | 0.0 | 34.4 | 72.7 | 47.7 |
| Centralized | 64.3 | 37.5 | 69.2 | 50.0 | 42.9 | 28.6 | 51.6 | 79.9 | 57.8 |
| FedAgent | 80.0 | 75.0 | 53.8 | 37.5 | 83.3 | 50.0 | 64.1 | 83.2 | 61.7 |
Qwen2.5-3B-Instruct
| Method | ALFWorld (Success Rate %) | WebShop | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pick | Look | Clean | Heat | Cool | Pick2 | All | Score | Succ. | |
| Local (Client 21) | 41.5 | 12.5 | 34.9 | 51.0 | 18.9 | 21.2 | 31.3 | 59.8 | 55.0 |
| Local (Client 42) | 46.5 | 37.5 | 24.4 | 15.0 | 33.7 | 33.3 | 28.2 | 61.3 | 59.3 |
| Local (Client 84) | 22.8 | 27.5 | 39.1 | 46.3 | 48.3 | 36.5 | 29.9 | 77.6 | 58.6 |
| Centralized | 94.1 | 80.0 | 64.3 | 42.9 | 50.0 | 22.2 | 62.5 | 86.0 | 63.9 |
| FedAgent | 95.5 | 62.5 | 49.7 | 47.5 | 85.3 | 45.1 | 65.2 | 85.5 | 63.1 |
Qwen2.5-7B-Instruct
| Method | ALFWorld (Success Rate %) | WebShop | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pick | Look | Clean | Heat | Cool | Pick2 | All | Score | Succ. | |
| Local (Client 21) | 35.5 | 25.0 | 61.0 | 25.9 | 35.8 | 45.2 | 38.4 | 70.9 | 49.2 |
| Local (Client 42) | 29.0 | 45.0 | 18.8 | 25.6 | 15.9 | 38.0 | 42.1 | 85.2 | 33.6 |
| Local (Client 84) | 34.7 | 47.5 | 44.4 | 51.3 | 40.1 | 21.8 | 35.7 | 60.6 | 39.3 |
| Centralized | 93.7 | 82.5 | 71.5 | 47.9 | 63.2 | 31.9 | 73.3 | 78.8 | 64.7 |
| FedAgent | 94.5 | 85.0 | 56.0 | 62.5 | 86.7 | 42.8 | 75.5 | 89.0 | 68.9 |
Llama-3.2-3B-Instruct
| Method | ALFWorld (Success Rate %) | WebShop | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Pick | Look | Clean | Heat | Cool | Pick2 | All | Score | Succ. | |
| Local (Client 21) | 39.8 | 50.0 | 17.9 | 40.0 | 20.7 | 34.0 | 38.1 | 65.3 | 50.5 |
| Local (Client 42) | 18.2 | 55.0 | 41.9 | 34.3 | 41.0 | 25.0 | 35.0 | 67.0 | 51.0 |
| Local (Client 84) | 29.9 | 32.5 | 39.0 | 18.9 | 18.8 | 37.6 | 29.7 | 70.2 | 55.7 |
| Centralized | 72.4 | 62.5 | 59.3 | 45.2 | 53.7 | 27.9 | 54.9 | 76.3 | 56.2 |
| FedAgent | 83.7 | 57.5 | 60.6 | 55.9 | 65.3 | 24.9 | 61.2 | 74.4 | 57.8 |
Experiments
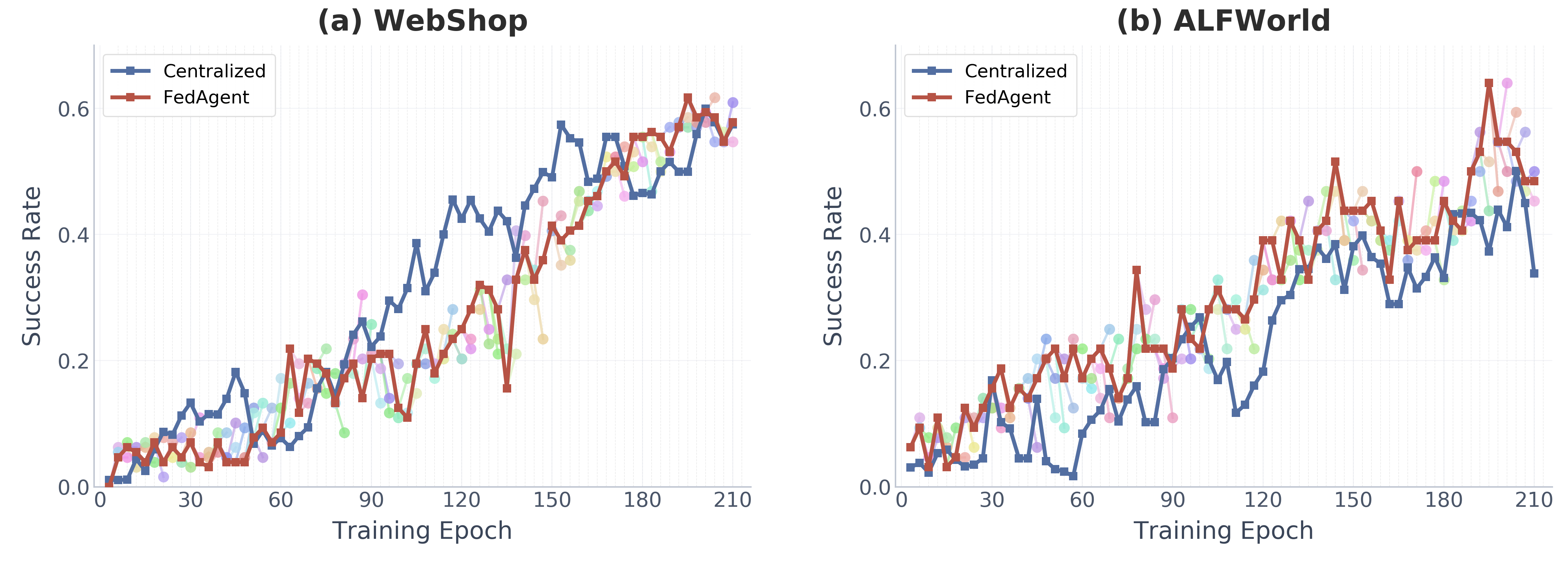
FedAgent Matches Centralized Training
FedAgent with 100 clients and 2 selected per round achieves comparable success rates to centralized training on all pooled data, despite never sharing local data.
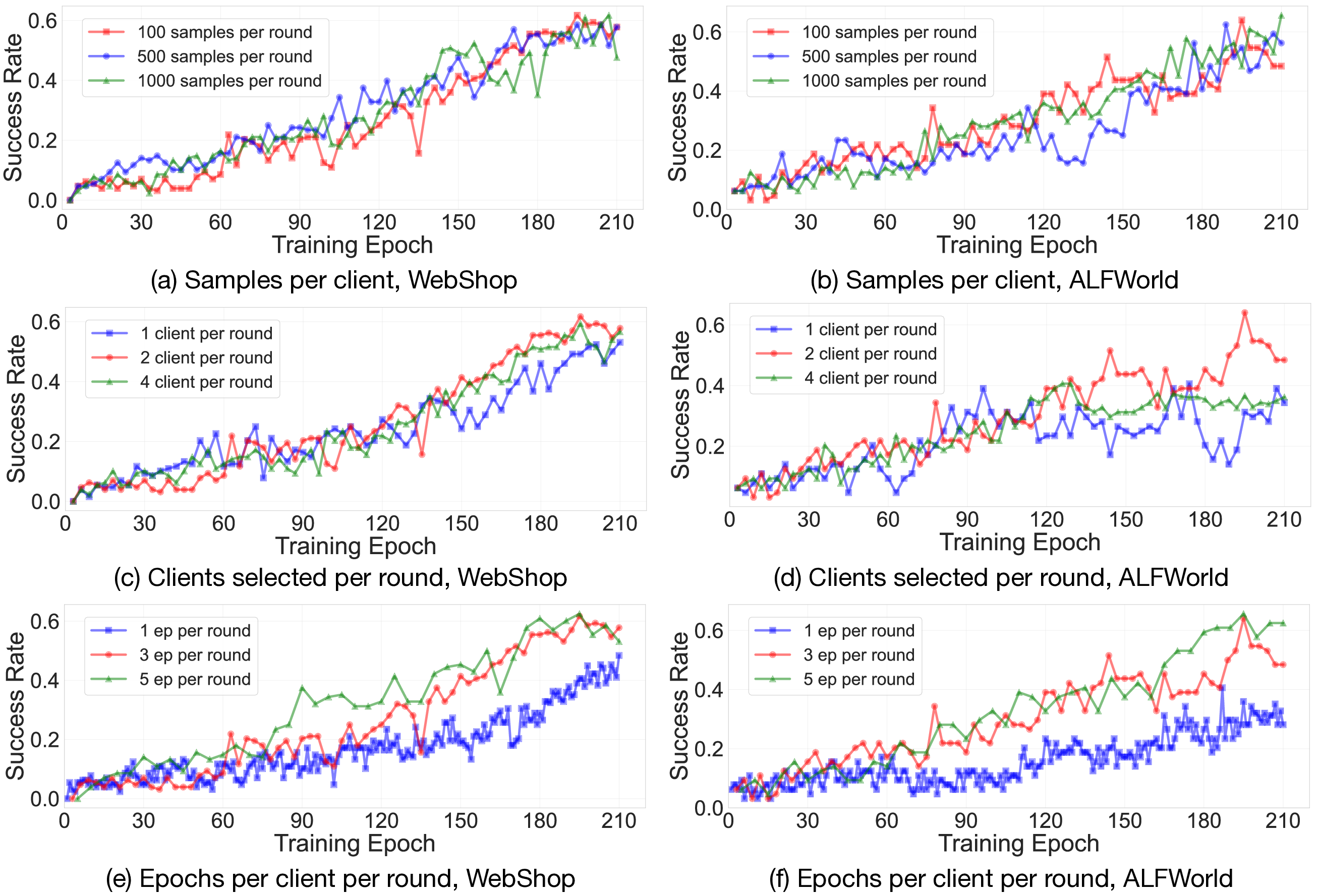
Training Dynamics in Different Decentralized Settings
FedAgent exhibits high sensitivity on the number of clients selected per round and epochs per client per round, while showing relatively low sensitivity to the number of samples per client.
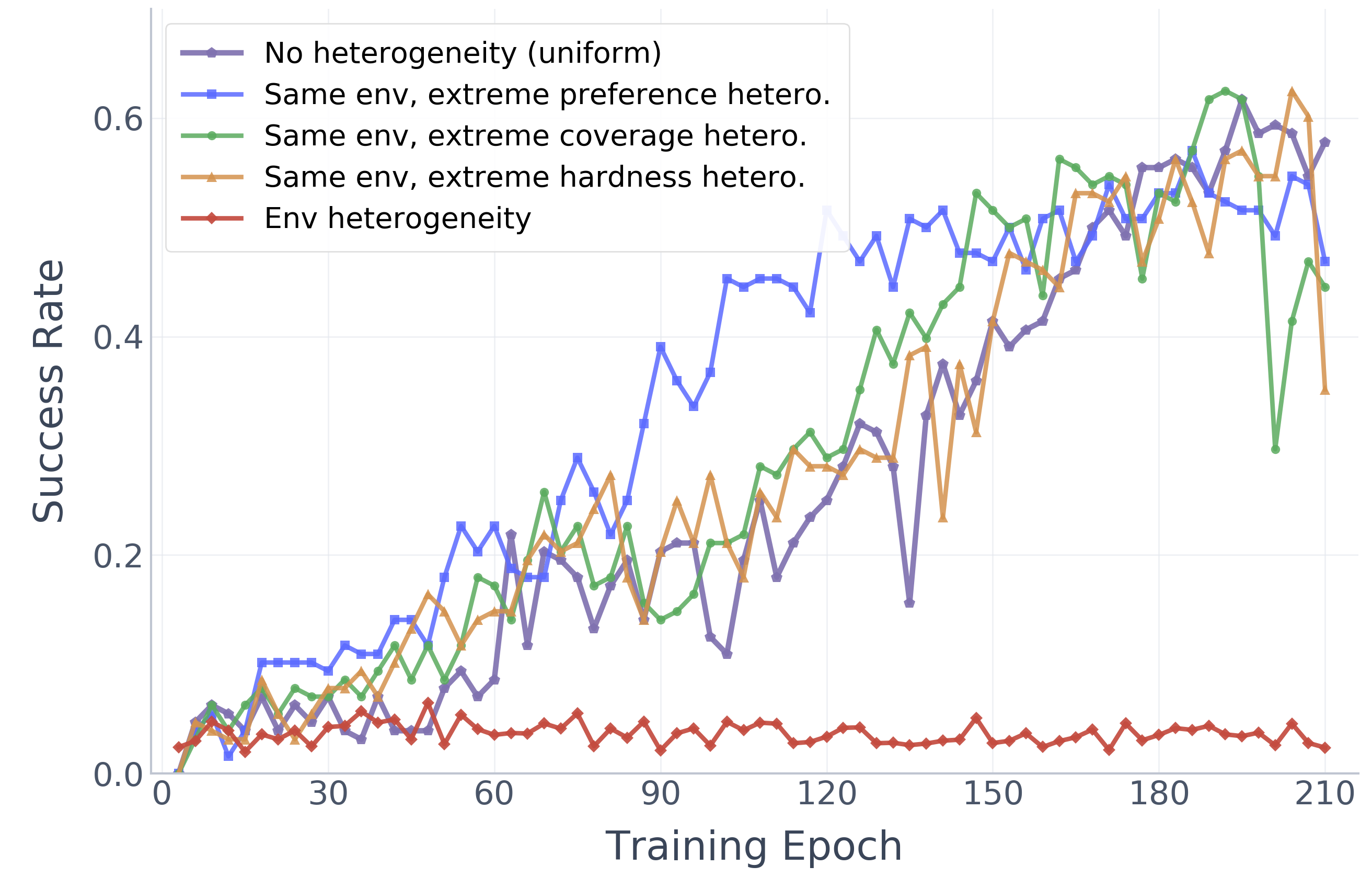
Two-Level Heterogeneity Analysis
Task mismatch alone barely affects training, but environment mismatch collapses the shared policy to near-zero, revealing the critical role of environment-level heterogeneity.
(a) WebShop
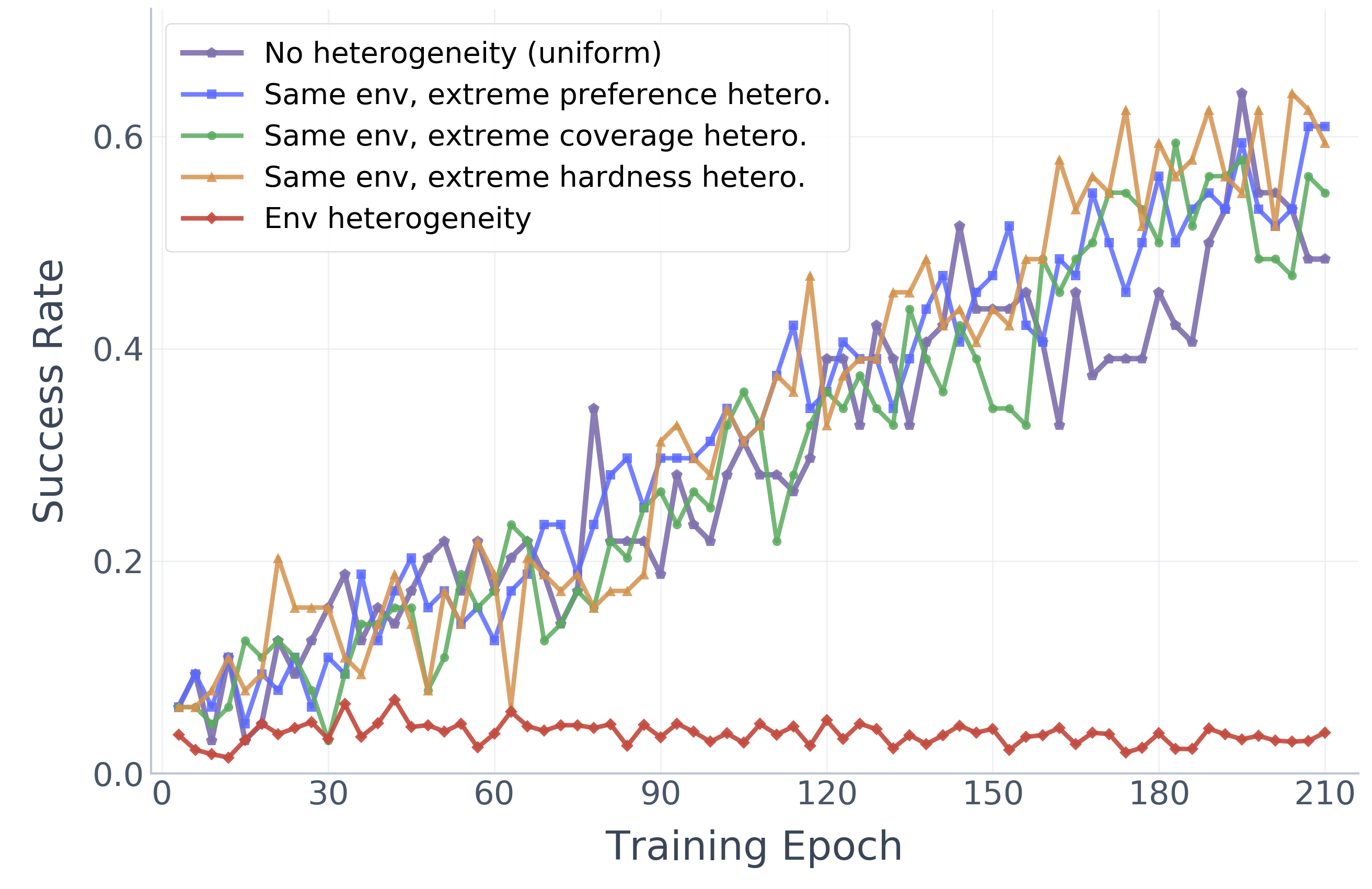
(b) ALFWorld
Theoretical Analysis
Why is FedAgent robust to task heterogeneity but fragile to environment heterogeneity?
Convergence Bound
We derive a convergence bound for FedAgent that decomposes the optimization error into three interpretable terms:
$\sigma^2$-Dominance Theory
In LLM agent settings, the exponential action space makes gradient noise $\sigma^2$ enormous. This has a surprising consequence:
Client Distributions under Partitioning Strategies
We visualize the client distributions under our three partitioning strategies across both WebShop and ALFWorld benchmarks.
Preference Preference Heterogeneity
Each client draws items from a client-specific categorical distribution over task types, controlled by jitter parameter ω. A larger ω produces more skewed per-client category mixes, modeling scenarios where different users strongly prefer distinct types of tasks.
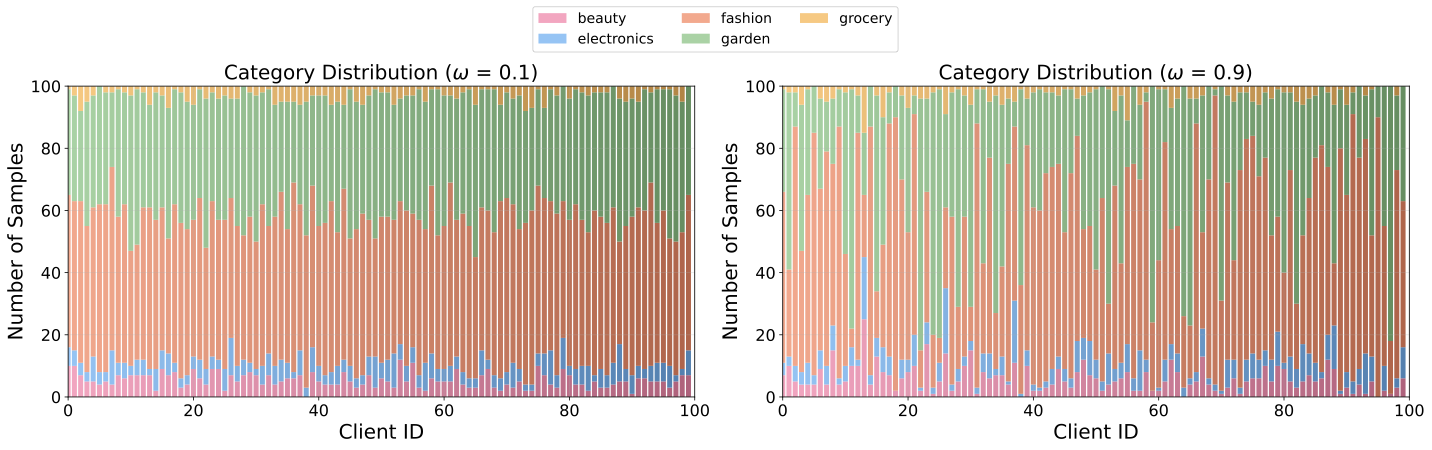
WebShop (ω = 0.1 vs. ω = 0.9)
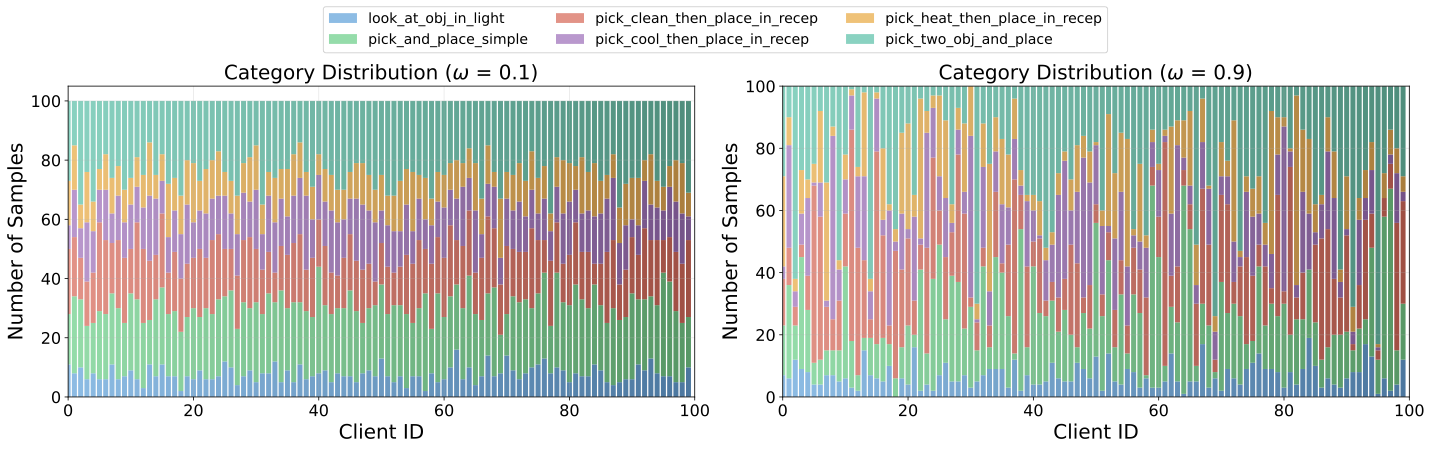
ALFWorld (ω = 0.1 vs. ω = 0.9)
Coverage Coverage Heterogeneity
Each client receives a different number of task instructions, controlled by dispersion parameter ξ. A smaller ξ leads to higher variance in client dataset sizes, modeling scenarios where some users have extensive task collections while others have very few.
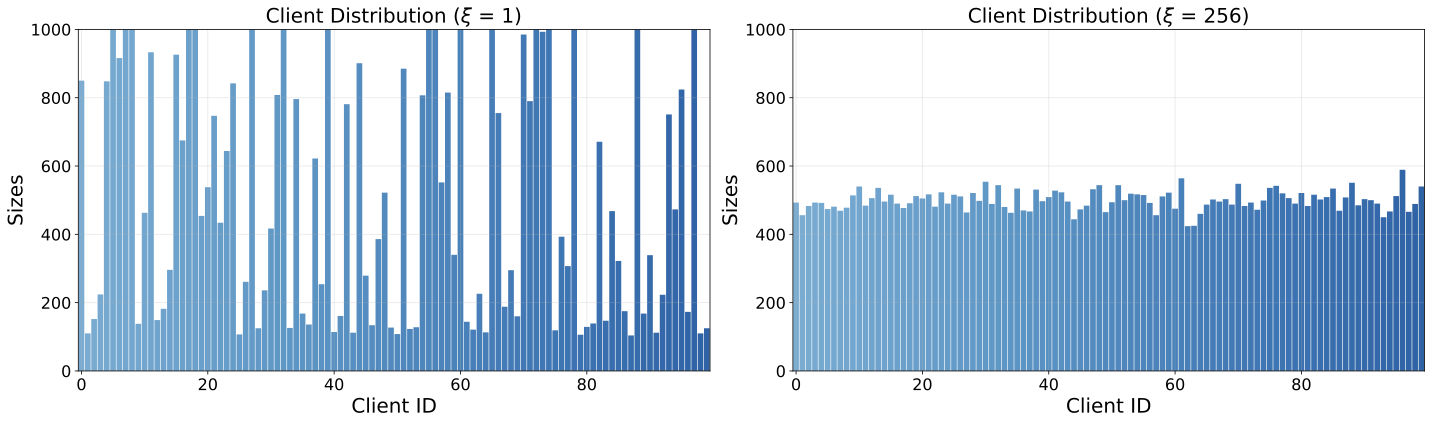
WebShop (ξ = 1 vs. ξ = 256)
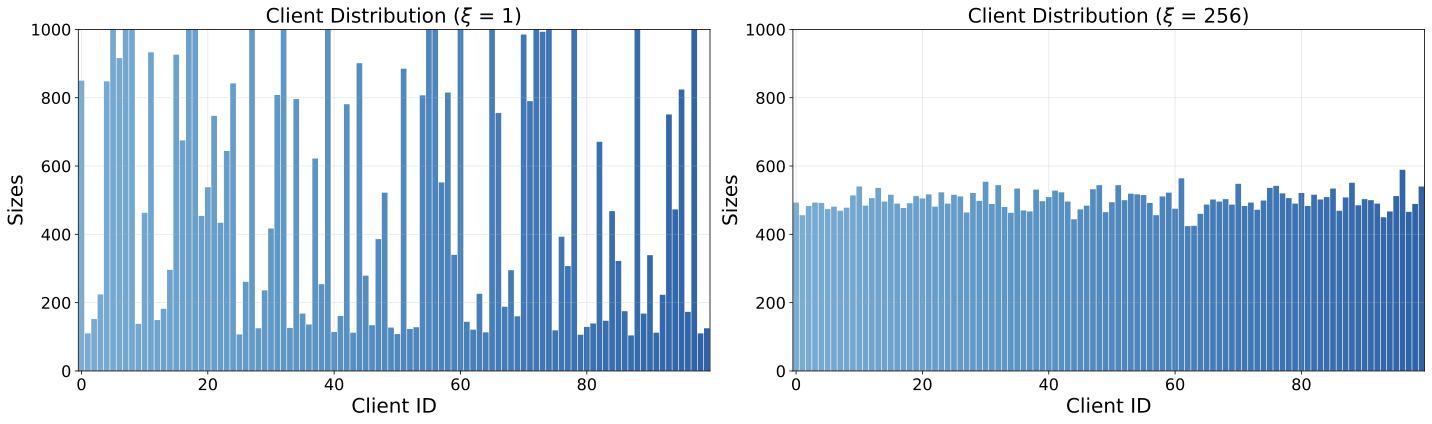
ALFWorld (ξ = 1 vs. ξ = 256)
Hardness Hardness Heterogeneity
Each client receives a different mix of easy (previously successful) and hard (previously unsuccessful) tasks, controlled by parameter ξ'. A smaller ξ' leads to higher variance in difficulty levels across clients, modeling scenarios where some users face predominantly easy tasks while others encounter mostly hard tasks.
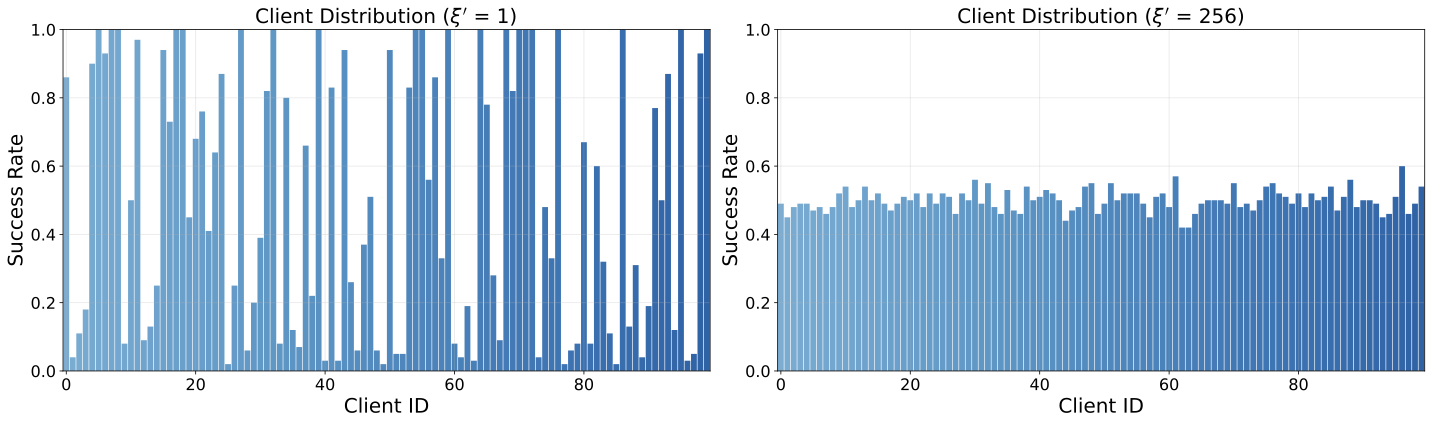
WebShop (ξ' = 1 vs. ξ' = 256)
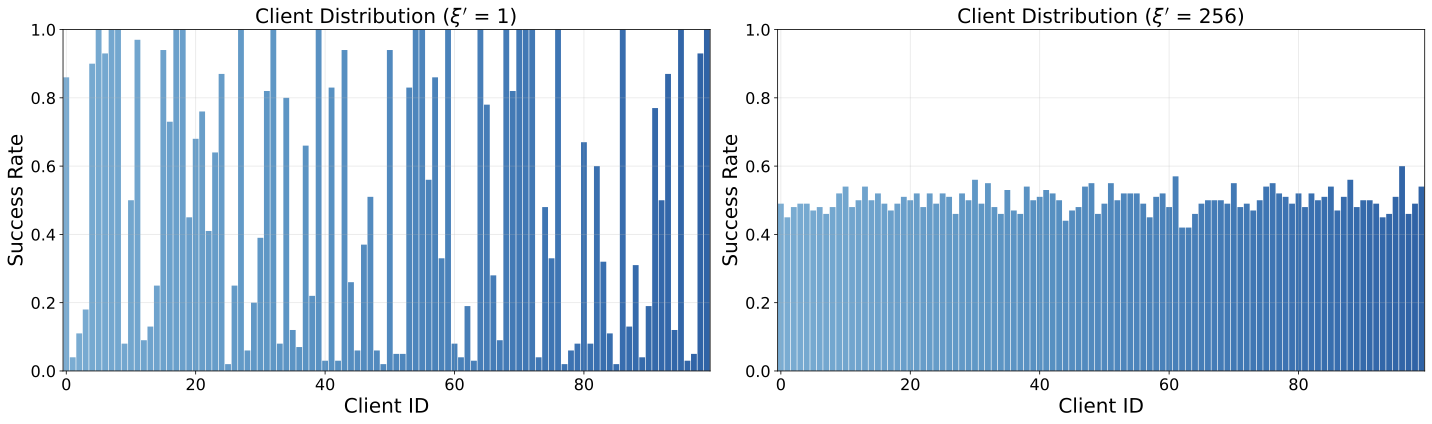
ALFWorld (ξ' = 1 vs. ξ' = 256)
Citation
If you find our work useful in your research, please cite:
@article{chen2025fedagent,
title={Federated Agent Reinforcement Learning},
author={Canyu Chen and Kangyu Zhu and Zhaorun Chen and Zhanhui Zhou and Shizhe Diao and Yiping Lu and Tian Li and Manling Li and Dawn Song},
year={2026},
journal={arXiv preprint},
}